Case Study: VisionaryOptics.com
Checkout modernization, prescription uploads + OCR, and payments expansion (WooCommerce)
Client: Visionary Optics
Platform: WooCommerce
Role: Peter Alcock — hands‑on lead (architecture + implementation)
Highlights: Prescription upload with OCR at checkout; multi‑processor payments (incl. crypto); measurable revenue lift in year one.
The challenge
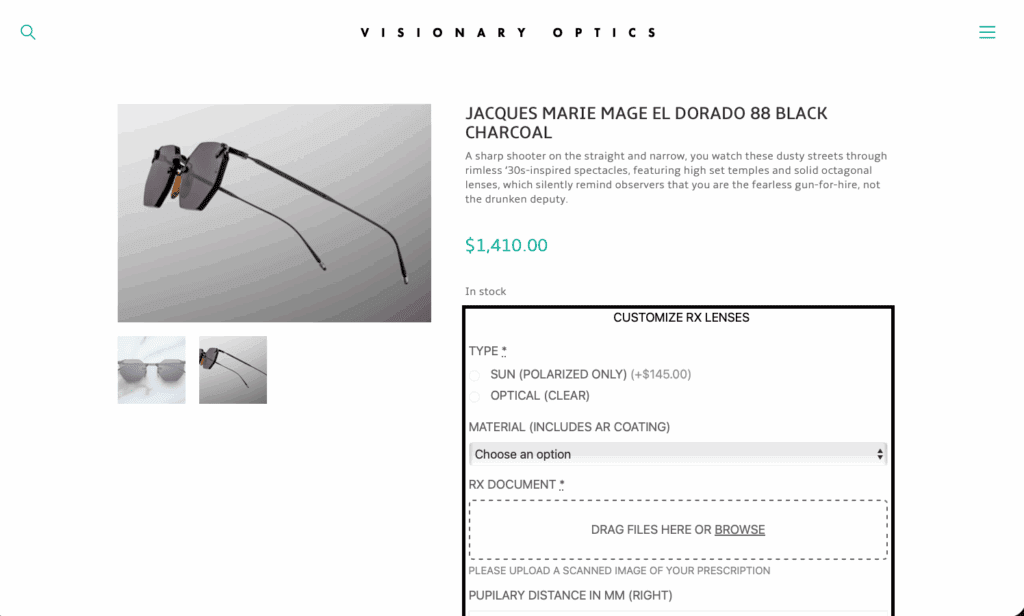
Visionary Optics needed a smoother path from product page to paid order—including a way to collect prescriptions during checkout and parse them automatically, and to accept more payment options without creating operational overhead.
—
What I built
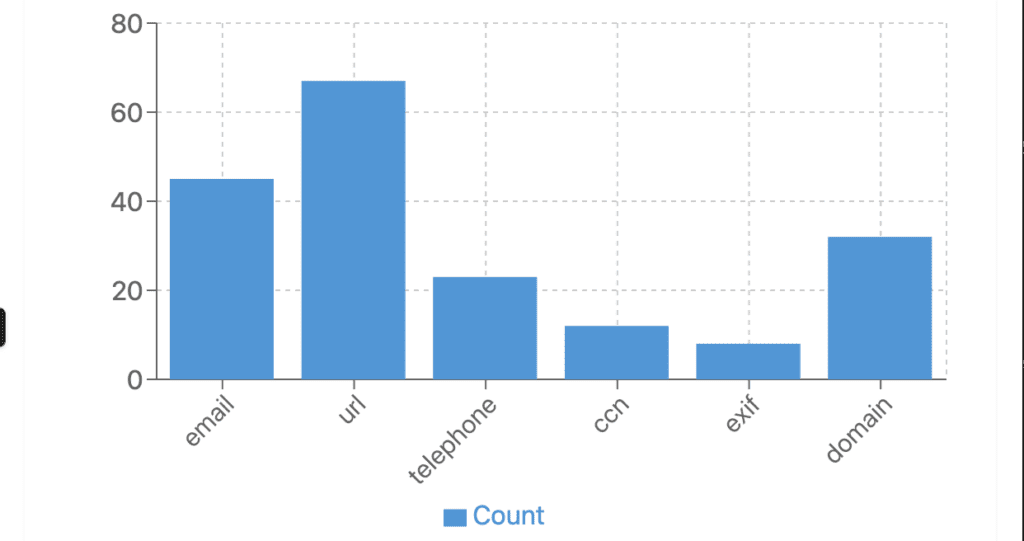
* Secure prescription upload at checkout with automated OCR parsing of key fields to reduce manual entry and speed fulfillment. (Referenced in my project summary on *page 3* of the uploaded application.)
* Payments expansion by integrating multiple processors, including a cryptocurrency option, while keeping the rest of the checkout flow unchanged for shoppers. (Also noted on *page 3*.)
* WooCommerce customization focused on reliability and visibility (clean error handling, basic instrumentation/logging, and admin‑friendly settings) so the team could self‑serve common changes.
* Tight client cadence: routine working sessions to iterate quickly on UX, validation, and operations fit. (*page 3*)
—
Results
* +$106,000 in incremental sales in the first year, attributed to the new checkout + payments work.
* Approximately a 3× ROI in year one on the engagement.
* Broader payment acceptance (incl. crypto) with no disruption to the existing checkout.
> Source: figures and scope as summarized in Peter’s application responses (*page 3* of the uploaded document).
—
Approach & principles
* Keep the shopper happy: fast pages, minimal extra steps, clear “why” when we ask for a prescription.
* Design for the ops team: make uploads legible, parsed, and easy to audit; keep settings in the admin.
* Small, safe iterations: ship behind flags, measure, then widen rollout.
* Own the edge cases: retries, idempotency where needed, and thorough request/feature tests around checkout.
—
Tech notes
* Stack: WooCommerce (WordPress), custom PHP/JS, OCR service integration, multiple payment gateways (plus a crypto processor).
* Key extensions: checkout flow hooks, file‑handling + validation, background parsing, and admin tools.
—
Before → After (at a glance)
* Manual prescription handling → Upload + automated parsing at checkout.
* Single/limited payments → Multiple processors and a crypto option.
* One‑off customizations → Configurable features the team can tune without code.